GTF>TC
Gene-Team Finder | Gene-Team-Tree Constructor
Description:Comparing multiple genome sequences is an important method to discover new biological insights. If a group of genes remain physically close to each other in multiple genomes, often called conserved gene clusters, then the genes may be either historically or functionally related. In recent years, several models had been developed to capture the essential biological features of a conserved gene cluster. The first such model was introduced by Uno and Yagiura, in which a genome sequence is considered as a permutation of distinct genes and a common interval is defined to be a set of genes that appear consecutively, possibly in different orders, in two given permutations. In the definition of common intervals, a single misplaced gene disqualifies the commonality between two otherwise similar intervals. To remedy this drawback, Béal et al. introduced the concept of gene teams. A gene team is a set of genes that appear in two or more species, possibly in a different order yet with the distance between adjacent genes in the team for each chromosome always no more than a certain threshold δ. Similar to the model of Uno and Yagiura, Béal et al. considered a chromosome as a permutation of distinct genes. They gave an efficient algorithm that finds the gene teams of two chromosomes in O(n log2 n) time, using O(n) space. In our paper, we improve the result from O(n log2 n) time to O(n log t) time, where t ≤ n is the number of gene teams.
|
|
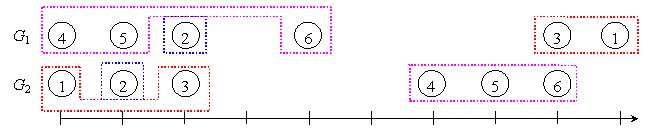
Formal Problem Definition:Let S be a set of n genes. A gene order G of S is a permutation of the genes in S, in which each gene a is associated with a real number PG(a), called its position, such that for any two genes a and b in G, PG(a) < PG(b) if a appears before b. Let G be a gene order of S. The distance of two genes a and b in G is given by |PG(a) − PG(b)|. For any subset S Í S, let G(S) be the gene order of S that is obtained from G by deleting the genes not in S. Let d ³ 0 be a real number. A subset C Í S is a d-chain of G if the distance between any two consecutive genes in G(C) is at most d. A d-chain C of G is maximal if there dose not exist any d-chain C' of G such that C' É C. Let G1 and G2 be two gene orders of S. A subset S Í S is a d-set of G1 and G2 if it is a d-chain of both G1 and G2. A d-team of G1 and G2 is a d-set that is maximal with respect to set inclusion. Given two gene orders G1, G2 of S and a real number d ³ 0, the gene team problem is to identify all d-teams of G1 and G2. It is easy to see that the d-teams of G1 and G2 form a partition of S. Example 1: Consider S = {a, b, c, d, e, f}, d = 3, and two gene orders G1 = (d1, e2, b3, f5, c9, a10) and G2 = (a1, b2, c3, d7, e8, f9), where the letters represent genes and the numbers in the subscript denote positions. Then, {d, e}, {e, f}, {d, e, f} are d-sets. The d-teams of G1 and G2 are {a, c}, {b}, {d, e, f}.
|
|
|
Gene-Team Finder [GTF][Source Code]
Sample Input: (Example 1)
6 // the number of genes 3 // the threshold d 4 1 // Gene order #1 (gene id, position) 5 2 // Gene order #1 (gene id, position) 2 3 // Gene order #1 (gene id, position) 6 5 // Gene order #1 (gene id, position) 3 9 // Gene order #1 (gene id, position) 1 10 // Gene order #1 (gene id, position) 1 1 // Gene order #2 (gene id, position) 2 2 // Gene order #2 (gene id, position) 3 3 // Gene order #2 (gene id, position) 4 7 // Gene order #2 (gene id, position) 5 8 // Gene order #2 (gene id, position) 6 9 // Gene order #2 (gene id, position)
Sample Output: (the gene teams)
{4, 5, 6} {3, 1} {2}
|
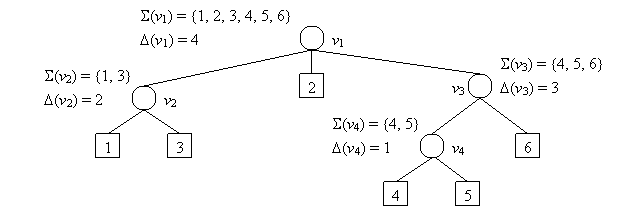
Description:A gene team tree is a succinct way to represent all gene teams for every possible value of d. Previous work is by Zhang and Leong, which takes O(n log2 n) time for constructing the gene team tree of two chromosomes. We propose a more efficient algorithm, which requires O(n log n loglog n) time.
|
|
Formal Problem Definition:Given two gene orders G1 and G2, the set of all d-teams for all possible values of d can be represented in a rooted tree, call a gene team tree, as follows.
1. There are n leaves, each of which stores a gene in S. 2. Every internal node v stores a value D(v), indicating that the genes in S(v) belong to the same d-team if and only if d ³ D(v), where S(v) is the set of genes stored in the subtree rooted at v. 3. The set of all S(v) corresponds to the set of all d-teams for all possible values of d.
The gene team tree of the gene orders G1 and G
|
|
|
Gene-Team-Tree Constructor [GTTC][Source Code]
Sample Input: (Example 1)
6 // the number of genes 4 1 // Gene order #1 (gene id, position) 5 2 // Gene order #1 (gene id, position) 2 3 // Gene order #1 (gene id, position) 6 5 // Gene order #1 (gene id, position) 3 9 // Gene order #1 (gene id, position) 1 10 // Gene order #1 (gene id, position) 1 1 // Gene order #2 (gene id, position) 2 2 // Gene order #2 (gene id, position) 3 3 // Gene order #2 (gene id, position) 4 7 // Gene order #2 (gene id, position) 5 8 // Gene order #2 (gene id, position) 6 9 // Gene order #2 (gene id, position)
Sample Output: (the gene team tree)
Node 1, 1, 4 // v1, parent(v1) = v1, D(v1) = 4 Node 2, 1, 3 // v2, parent(v2) = v1, D(v2) = 3 Node 3, 2, 1 // v3, parent(v3) = v2, D(v3) = 1 Gene 5, 3 // Gene 5, parent = v3 Node 5, 1, 2 // v5, parent(v5) = v1, D(v5) = 2 Gene 3, 5 // Gene 3, parent = v5 Gene 2, 1 // Gene 2, parent = v1 Gene 6, 2 // Gene 6, parent = v2 Gene 4, 3 // Gene 4, parent = v3 Gene 1, 5 // Gene 1, parent = v5
|